

Demigods and the almighty
To the software programs, we the programmers are the demigods, nearly the almighty. We decided how the little world inside a program worked. We made rules and we controlled how things were transformed in this program world.
However, we still relied on the programming language, the operating system, cables, chips, and electronics behind the scene. Therefore we are quite divine, but not almighty.
Without the ability to defy the law of physics, we have a lot of leeways in a program to navigate in order to automate processes and solve problems.
Let’s talk about application semantics
We definitely have the power to define the meanings of data structures and functions. Here we do not necessarily refer to the business meaning of them. It can do, but not under of the scope of the discussion here. We could define the functional meaning of different constructs or syntax within a program. A fancy term is the “Application Semantics”.
A simple example
I can give an example about Application Semantics.
Given there is a REST endpoint that handles the request of saving a number. The request body is a number. A success response returns HTTP status code 204, implying it was a success, i.e. the number is saved, but there is no content in the response body. An error in the request can be HTTP status code 406 for the number that cannot be accepted, or 413 if the number is too big, etc.
Those HTTP status codes, request body and response body are the syntactic constructs. “No content (Saved)”, “Not accepted”, “Payload too large” are the semantics of what the syntactic constructs actually mean. A human interprets HTTP status code 204 in this case as, “Oh my number is now saved”.
Let’s look at some of them now.
Create, Read, Update, Delete (CRUD)
This is the classic Application Semantics that divide operations into four categories.
| Operation | SQL Command | REST |
|---|---|---|
| Create | Insert | POST |
| Read | Select | GET |
| Update | Update | PUT |
| Delete | Delete | DELETE |
They are very clearly defined for what they mean from their literal names. CRUD implies that each resource can be uniquely identified, in other words, each resource is keyed on something. The key is used in all operations, so that for example, a Delete operation can be requested by just the key.
The current state is all that matters
Each resource being keyed by unique identifier implies that there is always a latest state of the resource. The historical states are replaced and forgotten. There is no duplicate resource by definition. Of course you could spawn a history item for the audit trail, but that resource is a resource of history, but the original resource itself. This is in short the “Start of the World” semantics.
CRUD is best used in the problem where the current state is the only thing that matters. The old states are quickly disposed and it is easy to get the latest states. In the financial world, real-time market data distribution is a the classic use of CRUD.
The market data client subscribes the market data identified by the symbol of the financial instrument. The first response is the current state of the item requested. Any update or deletion are pushed to the client as the client subscribed to the item. Also the symbol list or security list informs the client the creation of a new item. Live trading cares only the latest market data to the point that any old market data are discarded using conflation.
Summary of CRUD
In one sentence, CRUD is the semantics of “What is the current state?”.
- Four types of operation : Create, Read, Update and Delete.
- Current state of the world is all that matters.
Event Sourcing (ES)
On the other hand, Event Sourcing sees the world has an incremental sequence of events that shapes the state of the world continuously. There are numerous versions of the state of resource, and applying all events up to the latest event equals to the current state.
History and Traceability
All events are kept forever and you can go back in time to see a historical state. The aggregate root can still be keyed, and if it does, each event only concerns one aggregate root, and events of that aggregate root becomes effectively the stream of events. Creation is equivalent to the start of stream; Update is just an event in the stream; Deletion is the end of stream; and Read is interpretation of events while traversing of the stream.
Practically the program keeps the latest state so that it could compute the next event and next state faster. It can be described as:
new state = play(event, state)
The current state can be computed by re-playing all events in chronological order until the latest. Please note that the state here refers to a state that concerns one and only one aggregate root. An optimisation would be to aggregate old events in a snapshot so the program only needs to re-play the events not included in the snapshot. This is called the “Memento” pattern.
Since we intend to store all events, your event format must be backward compatible at all time. There are many techniques how to do it which will not be covered here.
Event Sourcing is best used in the problem where history matters and there is need to trace the causality of state changes. Using an example in Financial world, anything that needs to operates with the current state and required to have audit trails would be an excellent fit, such as a book of client orders. When queried by authorities or regulators, we could re-play event by event and work out how we ended up with the current state. Just like debugging our code line by line, Event Sourcing can be used to step through the state change event by event.
Summary of Event Sourcing (ES)
In one sentence, Event Sourcing is the semantics of “How did it get to the current state?”.
- History as the linear sequence of events
- An event, or a state should concern one and only one aggregate root.
- The state of the world is constructed by playing events.
- You could step through the change of the state event by event.
- The current state is practically useful in working out the next event.
- Memento pattern can be used as an optimisation to recover the current state.
- Event format must be backward compatible.
Command Query Responsibility Segregation (CQRS)
CQRS explicitly segregates read and write operations as “Query” and “Command” respectively. The fundamental idea is to model the domain as close as how human describes it.
For example, if we were to manage each contact in our phone. There are several possible actions:
- Categorise as “Family”, “Friends”, and “Business”
- Update an address
- Add a contact
- Delete a contact
- Find all contact’s first names by given surname
If we were to apply CRUD, the operations will become
- Create a contact
- Read contacts by surname
- Update a contact
- Delete a contact
which are not intuitive and adds mental load to translate real-life operations into the APIs.
Applying CQRS, the operations will become
- Categorise Contact Command
- Update Address Command
- Add Contact Command
- Delete Contact Command
- Find All First Names By Surname Query and they are much closer to our cognitive understanding of the operations.
That is why CQRS is always used together with Domain-drive development (DDD) so we could use the Ubiquitous Language in our codebase. So no more translation!
Another observation is that the query return exactly what the clients wanted (as a report). Nothing more nothing less. It is a de-normalised and customised report for the given query. And the query will need to provide exactly what the clients have in hand. This will naturally fulfil the Interface Segregation Principle.
Join force with Event Sourcing
CQRS and Event-sourcing complement each other, but it is not a must to use them together. If there is no need to keep history, then CQRS alone would be sufficient.
The gotcha is that how command and event are related because they both change the current state. Actually it is quite simple:
event = execute(command, state)
Literally translated to given the state X, when there is a command Y, then event Z is generated. And then of course:
new state = play(event, state)
that translated to given the state X, when event Z is played, then the state X' is generated.
So they work perfectly together!
Here I must remind you that if you were to use them together, then
- Only use it within a bounded context. Absolutely avoid any cross-domain commands and events. Leaking anything outside bounded context will haunt you forever.
- The update of the aggregate root must never leak out of the bounded context. It is called “bounded” for good reasons.
- Business decisions should be 100% made in the command execution, and the event captures that decision only. This is to ensure the application can evolve over time.
- Having said above, it is normal to listen to an external domain’s event and react to it. I’ll cover this later.
- All states, commands and events are immutable to ensure deterministic behaviours.
- The
executeandplayfunctions must be stateless (Pure function) to ensure deterministic behaviours. - Any timestamp and randomised value must be fed from outside the domain as absolute values. Otherwise the result is indeterministic.
- Use Functional Programming as the programming constructs as it ensures deterministic behaviours by persistent data structures and stateless functions.
Define the events properly
An event should be named using the ubiquitous language that all stakeholders should understanding. The event should map to the events that were brought up during the Event storming session.
There may be cases where you need to distinguish between internal and external events, or between domain and integration events. My general comments to them are:
- If it is so “internal” that you don’t want outsiders to know, it’s probably not worth putting that event in the event store.
- If it belongs to “integration” that outsiders need to know, then I wonder why that cannot be under a business context. Unless this is not coming from a business requirement, you could always have an appropriate event using business language.
I still do not buy the idea of “internal” and “integration” events, at least not yet.
Summary of CQRS
- Segregation of command (intent on writing) and query (intent on reading)
- Event is the outcome of a command
- Report is the outcome of a query
- Command, event, query and report are all customised to the business cases with the use of ubiquitous language.
- CQRS is always used together with DDD
- CQRS is naturally compatible with ES, but not necessarily always bundle together
Reactive Programming
Reactive programming focuses on asynchronous data stream processing and propagation of change. So basically it is the plumbing of data streams and the observer’s reaction to the data in the stream.
It could take a form that looks similar to what we have discussed: Given the state A, when there is event B, then state C and event D are generated. And then there will be a chain and/or branches of reaction happening afterwards.
This is the bit I said I would cover later, which is when domain A observes the events from domain B and react to it. This is nothing magical because the classical pub/sub mechanism is one of the implementation already.
However, there must be a beginning of everything is it not? What is it?
Let’s mix in more…
How about command? Is command the beginning? But who gave the command? There are usually two sources of command:
- User actions
- Scheduled jobs
From the command generated by the above, it enters the domain to have the events generated. After the domain itself consumed the event and updated its state, the other domains observed this event and reacted to it. Thus more events from other domains are generated, and so on. It is a domino effect.
If it was coded using the imperative way, it could have the exponential number of possibilities. It would be very hard for a programmer to mentally manage all these in the head. Imagine we coded it with the classic if (condition A) then (if condition B then) .... My small brain would not be able to handle it.
But I could easily handle in a reactive way (e.g. do this when event A happened) and I focus on one thing at a time (Single Responsibility Principle). I could scale it up when I have more things to do by adding additional observers reacting to the event asynchronously.
Summary of RP
- Asynchronous data stream processing
- Propagation of changes
- There are a lot of plumbing of streams like merging, filtering etc.
- Pub/sub is already one of the implementation
The bigger picture
If you put everything together, it become like this:
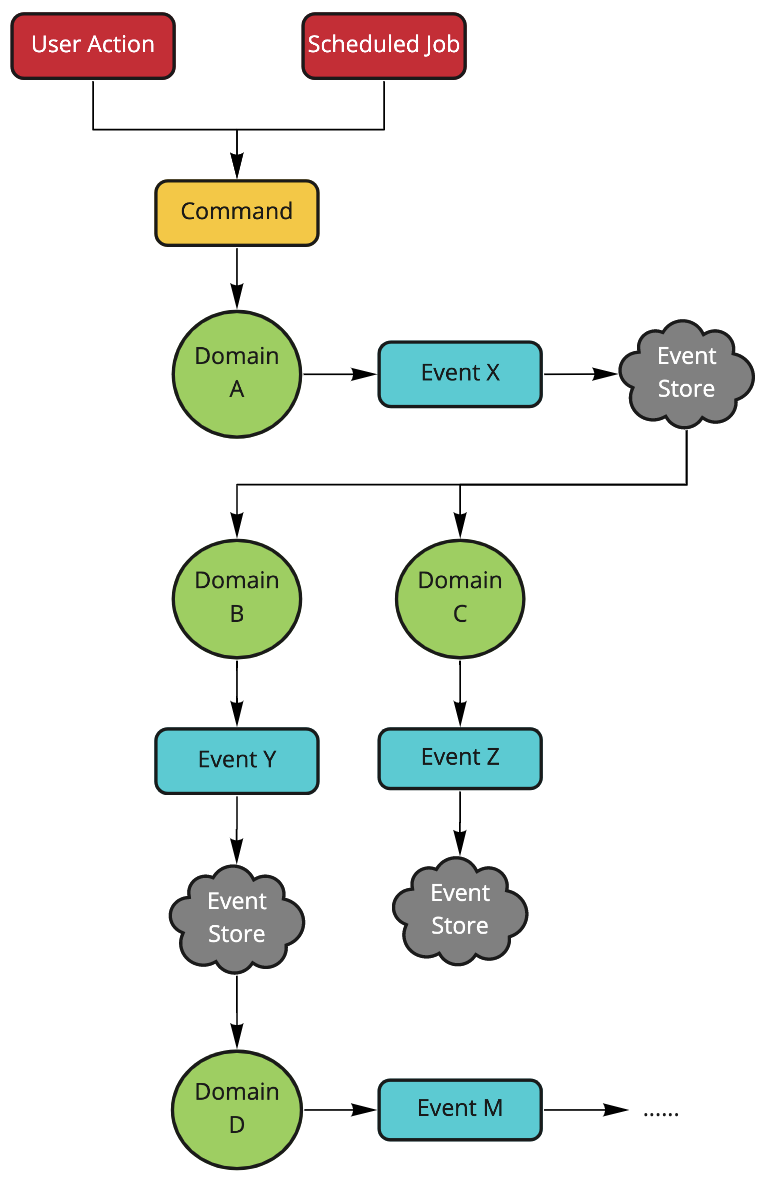
Please note that the “Event Store” was drawn independently for each domain to indicate they are logically different event streams. It does not enforce the separation and you could still mix them and filter them at the observer side.
Recommendations
I strongly recommended applying Functional Programming, SOLID Principles and Hexagonal Architecture in this combination to ensure the deterministic behaviours and consistency. Also I did not abandoning Object-oriented programming (OOP) by using Functional programming (FP). I have another article here to go into the details.
The bounded context must be sensibly defined before you apply this combination. Each domain should apply its application semantics independently.
These application semantics are agnostic to any library or technology. Using a library for CQRS does not migrate your application semantics automatically. Application Semantics is the meaning you make out of the design.
All these semantics can be applied independently, and you must have good reasons to mix any one of them together.
By the way…
I have struggled for months in writing this article. The main reason was that I did not feel I learned enough to combine all these concepts together. So I went back to my personal projects to explore. Also I was in the middle of changing jobs and country of residence that did not help me concentrate on this.